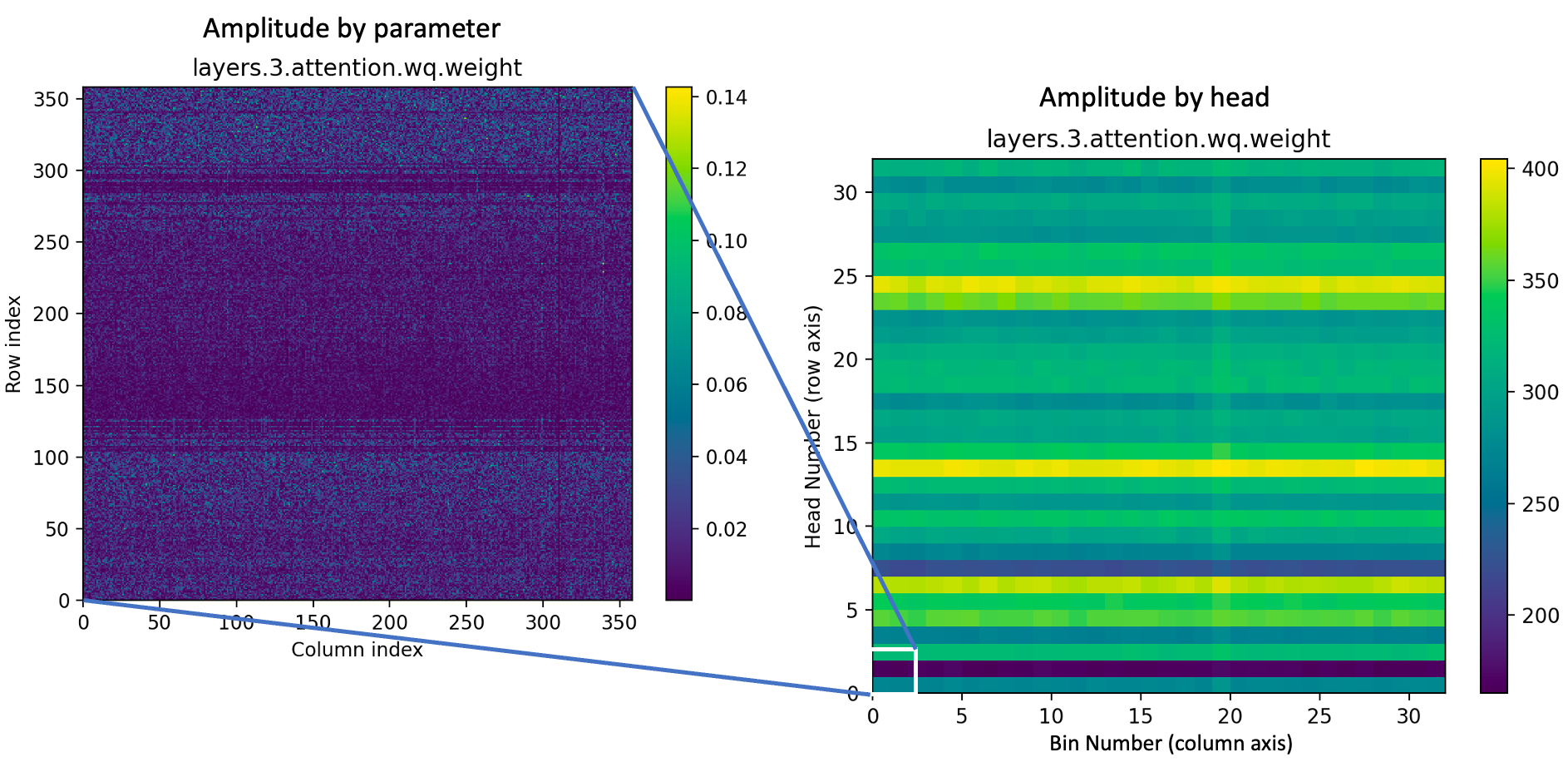
Figure 2: Query parameter values (Wq) in the 4th transformer layer. (left) The absolute value of matrix elements
in a corner of the 4th-layer Wq tensor. The dark stripe from row index 128-255 is a ‘quiet’ attention head’.
(right) Absolute values of the Wq matrix are binned by a factor of 128 to show the entire matrix. The ‘loudness’
of an attention head can be seen from the brightness of the horizontal stripe it indexes.
A few notes:
- The 4096x4096 view (or 32x32, after 128x binning), as it highlights that some attention heads (horizontal stripes) are significantly brighter than others. This is most true for the first two layers, which will be looked at separately.
- There are also bright rows within the heads, representing encodings that the heads are particularly looking for. More on this later.
- There are also bright columns, representing encoding elements that are significant to multiple heads. As a somewhat trivial example,
matrix elements coupling to the first token (x0 coming from the transformer input) will tend to be bright -for all heads- due for deeper
transformers to the attention sink effect. This is another thing I’ll try circle back around to.