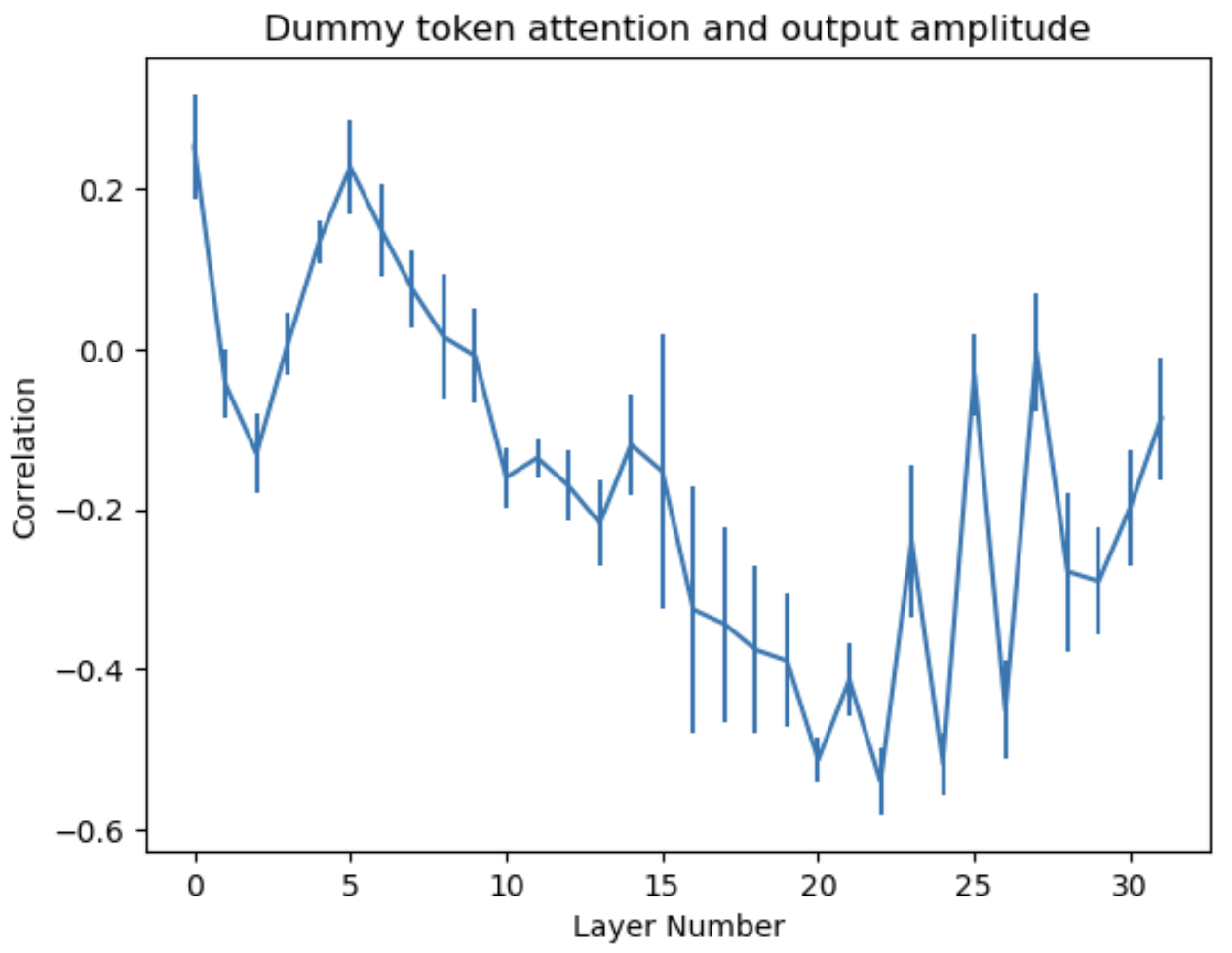
The figure shows a quick look at how the amplitude of the attention sink effect a transformer correlates with the L2 norm of the transformer's output vectors. Layer ‘0’ is the first transformer. Four prompts were used with ~200 characters each, and the first 80 characters were discarded to ignore the ‘first sentence highlighting’ effect. Error bars show standard error between the four prompts.